Visão Computacional Avança…

7 minutos para ler

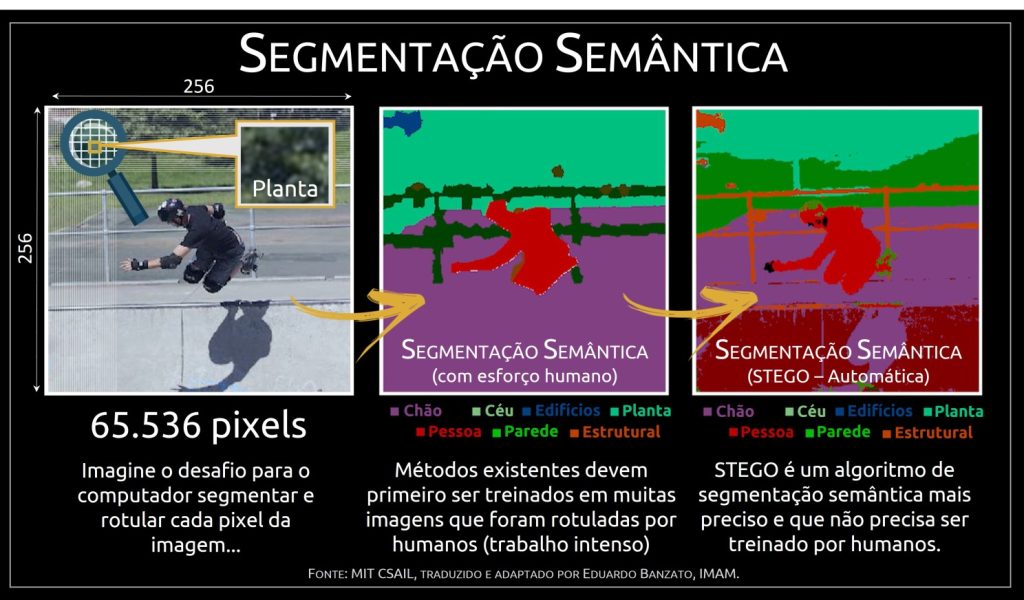
Cientistas do Laboratório de Ciência da Computação e Inteligência Artificial do MIT (Massachusetts Institute of Technology) merecem mais uma vez os parabéns, pois criaram recentemente um novo algoritmo (STEGO), para resolver uma das tarefas mais difíceis da visão computacional: atribuir um rótulo a cada um dos 65.536 pixels individuais que compõem uma única imagem de 256 x 256, sem a participação humana.
Assista o video do MIT CSAIL AQUI.
Vamos a seguir conhecer melhor este avanço que dará à Inteligência Artificial (IA) uma visão ainda mais precisa e, obviamente, isto terá também um impacto direto nas soluções de Manufatura e Logística (Supply Chain).
Há anos a indústria já trabalha com a visão de máquina, com foco principalmente na qualidade dos produtos, mas a Visão Computacional avança rapidamente e ainda são poucas empresas que perceberam os potenciais de melhoria nos processos a partir da mesma.
DESAFIOS DA VISÃO COMPUTACIONAL
A natureza humana é tão perfeita que nós, seres humanos, conseguimos identificar com nossa fantástica capacidade (visão + cérebro), em uma simples imagem, os diferentes elementos (pessoas, animais, plantas, edifícios…) mas, para a Inteligência Artificial, isto não é tão simples assim e demanda um grande esforço de treinamento.
Para exemplificar, em alguns projetos de inventário, aqui mesmo no Brasil, algumas equipes desistiram rapidamente da Visão Computacional ao perceber que a mesma não reconhecia as imagens que desejavam (determinados SKUs) e outros seguiram em frente e descobriram os desafios e as oportunidades da Visão Computacional. Mas poucos ainda compreendem que o algoritmo necessita ser treinado e é por isso que insistimos em treinamentos mais abrangentes de tecnologia aplicada à Supply Chain para profissionais de logística e manufatura (exemplo: Supply Chain Tech), para que os mesmos não desistam nas primeiras dificuldades da aplicação da tecnologia. Boa parte dos projetos do time IMAM tem passado por estes desafios.
ENTENDENDO A TECNOLOGIA
Geralmente, sistemas mais convencionais de treinamento de Visão Computacional envolvem uma caixa em torno de objetos específicos (veja figura a seguir).

Uma caixa ao redor de uma empilhadeira, de uma pessoa, de um capacete etc. Rotular estas caixas, destacando o que está no seu interior (ex.: “pessoa”) é fundamental para a IA ser treinada e também que a mesma seja capaz de distinguir uma “pessoa” de uma “empilhadeira”, de um “capacete” etc.
STEGO: NOVO ALGORITMO DE VISÃO COMPUTACIONAL
O algoritmo STEGO (“Self-supervised Transformer with Energy-based Graph Optimization”) usa uma técnica já conhecida como Segmentação Semântica (observe a figura e o filme já apresentados) que aplica um rótulo de classe a cada pixel da imagem e não da caixa. Assim, fornece à Inteligência Artificial uma visão muito mais precisa da realidade.
Considerando que, no método anterior, uma caixa rotulada teria não apenas o objeto, mas outros itens nos pixels circundantes dentro do limite “encaixotado”, a segmentação semântica já evoluiu rotulando cada pixel no objeto e apenas os pixels que compõem o objeto. Se você tem, por exemplo, uma pessoa operando uma empilhadeira, a segmentação semântica separa com maior precisão a pessoa da empilhadeira.
Mas o desafio desta técnica é que a mesma demanda milhares de imagens rotuladas (horas de trabalho) com as quais o algoritmo será treinado e isso pode se tornar inviável para determinadas aplicações. Assim, atribuir a cada pixel existente no nosso mundo um determinado rótulo é muito ambicioso, especialmente se considerarmos que este processo seja realizado de forma automática, sem qualquer tipo de “feedback” humano (proposta do algoritmo STEGO).
Para descobrir esses objetos sem a orientação de um ser humano, o STEGO procura objetos semelhantes que aparecem ao longo de “datasets” (conjunto de dados). Em seguida, associa esses objetos semelhantes para construir uma visão consistente da realidade a partir de todas as imagens já aprendidas.
O STEGO foi testado em uma série de domínios visuais que abrangem imagens gerais, imagens de condução e fotografias aéreas de alta altitude. Em cada domínio, o STEGO foi capaz de identificar e segmentar objetos relevantes que estavam estreitamente alinhados com os julgamentos humanos.
A referência mais diversificada da STEGO foi o dataset “COCO-Stuff”, que é composto por diversas imagens de todo o mundo, desde cenas internas, pessoas praticando esportes até árvores e vacas. Veja a seguir e acesse AQUI no GitHub o dataset.
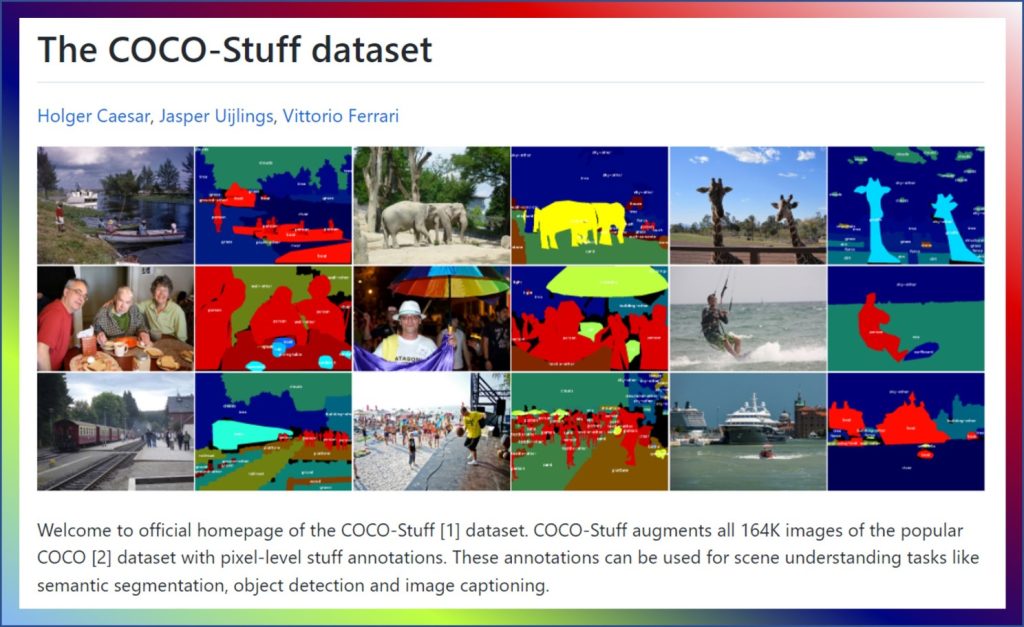
Os sistemas anteriores mais avançados poderiam capturar a essência de uma cena, mas pecava nos detalhes finos. Por exemplo, uma motocicleta poderia ser capturada como pessoa. Nestas mesmas cenas, o STEGO dobrou o desempenho dos sistemas anteriores e descobriu animais, edifícios, pessoas, móveis e muitos outros.
O algoritmo STEGO também deu saltos semelhantes em outros domínios visuais. Quando aplicado a datasets de veículos autônomos, segmentou com sucesso as estradas, pessoas e placas de rua, com resolução e granularidade muito superiores aos sistemas anteriores. Em relação às imagens do espaço (ex.: mapas), o sistema segmentou cada metro quadrado da superfície da Terra em estradas, vegetação e edifícios.
Além disso, o STEGO se baseia no algoritmo DINO, que aprendeu sobre o mundo por meio de 14 milhões de imagens do banco de dados ImageNet (acesse AQUI no GitHub). A STEGO refinou a espinha dorsal do DINO através de um processo de aprendizagem que imita nossa própria maneira de costurar pedaços do mundo para fazer sentido.
“A ideia é que esses novos tipos de algoritmos (STEGO) possam encontrar agrupamentos consistentes de forma automatizada para que não tenhamos que fazer isso nós mesmos”, diz diz Mark Hamilton, doutorando em engenharia elétrica e ciência da computação no MIT, afiliado à pesquisa do MIT CSAIL e engenheiro de software da Microsoft.
Acesse aqui STEGO no GitHub (Mark Hamilton).
APLICAÇÃO NA REALIDADE BRASIL
Por que devemos dar destaque a visão computacional aqui no Brasil?
Em primeiro lugar, sistemas que podem “ver” são cruciais para uma ampla gama de tecnologias emergentes, como veículos autônomos, modelagem preditiva etc. e como o STEGO pode aprender sem a necessidade de esforço humano, certamente poderá ajudar a acelerar a aplicação em um país carente de mão de obra especializada.
Segundo, em função da conhecida dificuldade de nosso Estado, a maioria das empresas no Brasil, principalmente as pequenas e médias, não terão no curto prazo a mesma facilidade que países mais desenvolvidos têm para implementar sistemas automatizados. Assim, por meio da Visão Computacional, abriremos espaço para soluções mais simples e funcionais, que hoje até já fazem parte de algumas empresas aqui no nosso país, mas que certamente avançarão muito mais.
AINDA COM LIMITAÇÕES, MAS JÁ É REFERÊNCIA
Apesar de seu desempenho superior, o algoritmo STEGO tem suas limitações… por exemplo, ele até pode identificar massas e grãos como “produtos alimentícios”, mas não os diferencia muito bem. Além disso, também pode ficar meio confuso com imagens sem muito sentido como por exemplo, se você apoiar uma banana sobre uma base de telefone, onde um ser humano perceberia facilmente a realidade, os algoritmos ainda avançarão cada vez mais.
“Considero a segmentação não supervisionada (STEGO) uma referência para o progresso na compreensão da imagem e um problema muito difícil. A comunidade de pesquisa fez um progresso fantástico na compreensão de imagens de forma não supervisionadas”, destaca Andrea Vedaldi, professor de Computer Vision e Machine Learning do departamento de ciência de engenharia da Universidade de Oxford.
Parabéns a todo time MIT e vamos em frente…
Boa semana a todos!
Fonte: artigo de Rachel Gordon, MIT CSAIL: A new state of the art for unsupervised computer vision | MIT News | Massachusetts Institute of Technology