“Supply Chain Data Lake”

12 minutos para ler

Certamente você já deve ter se deparado, nos últimos anos, com o termo “Data Lake” ou “Lago de Dados” que, independentemente de sua arquitetura tecnológica, é um repositório de dados onde os mesmos ficam armazenados, em seu formato bruto, para uso corporativo.
Em um “Data Lake” podemos armazenar dados como eles são/estão, sem ter a necessidade de estruturá-los (como em um Data Warehouse) e mesmo assim poder executar diferentes tipos de análise dos dados.
ABRANGÊNCIA DO “SUPPLY CHAIN DATA LAKE”
Para aqueles que atuam na Supply Chain e conhecem as “profundezas” dos dados relevantes da Cadeia de Suprimentos, bem como da Logística e da Intralogística, certamente terão no “Data Lake” mais uma oportunidade para avançar em competitividade, principalmente enquanto a maioria das empresas/profissionais ainda não “despertaram”.
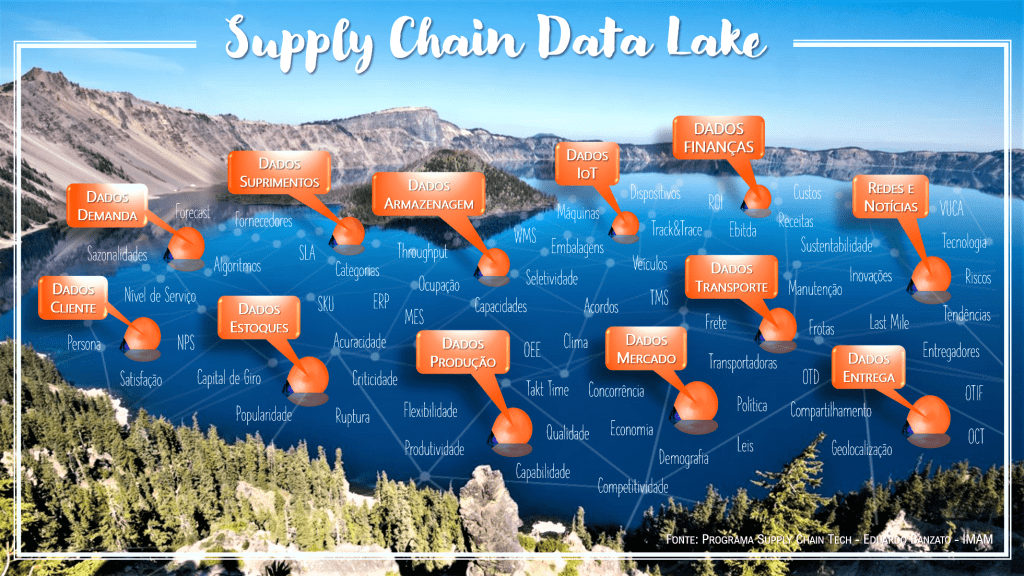
A figura acima não representa a arquitetura de um “Data Lake”, até porque a estrutura de “silos de dados” é mais característica do “Data Warehouse” mas, a ilustração destaca o universo de dados e como podemos explorar projetos de Data Lake, Big Data e Data Analytics aplicados à Cadeia de Suprimentos.
Vale lembrar que a tecnologia, por si só, não fará análises e tomará decisões estratégicas. É a capacidade dos cientistas de dados e dos especialistas de negócios que identificam possíveis dados relevantes que, aí sim, por meio da tecnologia, viabilizam análises e tomadas de decisão baseadas em dados (“data-driven”), bem como contribuem para a automação de decisões mais inteligentes por meio de algoritmos de Inteligência Artificial.
Este contexto tem nos levado, na cadeia de suprimentos, a atuar em times “multiespecializados”, que integram profissionais responsáveis por dados, especialistas de negócios (nas áreas Supply Chain – ex.: IMAM) e profissionais especializados em dados e tecnologia (ex.: Aquarela Analytics, pioneira e referência nacional na aplicação de Inteligência Artificial em empresas como Embraer, Grupo Randon, Solarbr Coca-cola e outros).
Além da necessária inteligência para lidar com dados na Supply Chain, hoje, com o avanço do armazenamento nas nuvens, podemos contar também com praticamente todas as grandes da tecnologia, tais como Google, Oracle, Microsoft, Amazon etc., que oferecem excelentes soluções de “Data Lake”.
Dica de Conteúdo: Anualmente, a IMAM realiza um programa de desenvolvimento profissional, Supply Chain Tech, com empresas de tecnologia aplicada à Supply Chain, pois são os profissionais que farão a diferença nos próximos anos (saiba mais AQUI).

ATENÇÃO E CUIDADO COM O “DATA SWAMP”
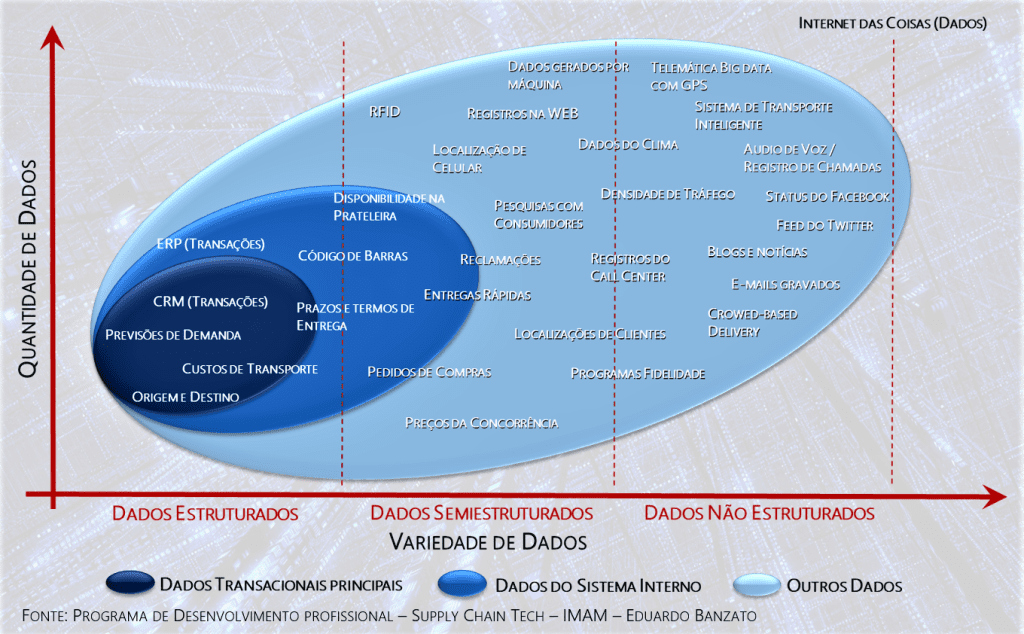
Um “Data Lake” inclui desde os tradicionais dados estruturados, passando pelos dados semiestruturados e os não menos importantes dados não estruturados (vide figura a seguir).

Perceba que os tipos e a quantidade de dados que podemos trabalhar na Supply Chain é muito grande e vale lembrar que a construção destes grandes bancos de dados já é, por si só, um grande desafio técnico. Por outro lado e não menos complexo, está a necessidade de processos coerentes de alinhamento multidisciplinar entre pessoas, processos e o negócio para que o tão esperado “Data Lake” com águas limpas (dados relevantes), não se torne um “Data Swamp” (pântano de dados) repleto de dados com pouco valor prático em tomadas de decisão.
Sim, e é aqui que “separamos o joio do trigo”… É aqui que as equipes mais bem preparadas e os profissionais com visão sistêmica e integrada são fundamentais. Não é uma questão de experiência e/ou juventude mais adaptada à tecnologia. Existem jovens profissionais hoje com habilidades sistêmicas bem desenvolvidas e outros que ainda precisam se desenvolver muito. Ao mesmo tempo, é exatamente isto que acontece com os mais experientes.
Por esse motivo que, no ambiente de Supply Chain, a IMAM e a AQUARELA desenvolvem programas específicos de formação profissional e/ou projetos que exploram exatamente estas carências profissionais na área de Supply Chain/Tecnologia e aproveitamos AQUI para destacar a seguir, na visão de Joni Hoppen e Eduardo Banzato, algumas dicas gerenciais (não tecnológicas), que são pontos de atenção não apenas para os profissionais de Supply Chain, mas principalmente aos gerentes, diretores de tecnologia da informação e CIOs que se envolverão nestes processos de construção e estruturação de “Data Lake” em Supply Chain:
01 – Supply Chain… só por meio de times de especialistas
A necessidade de conhecer toda a abrangência do ambiente de negócio que queremos explorar é básica. Hoje, não existe no mercado nacional e/ou mundial, profissionais especialistas em toda a Cadeia de Suprimentos. Isso acontece por um motivo muito simples, a abrangência e os desafios são tão amplos que um profissional, mesmo que dedique sua vida à Supply Chain, não consegue se especializar em todas as suas áreas.
Assim, qual é a solução?
“Precisamos trabalhar em times de especialistas que contribuem com a visão sistêmica e a gestão integrada de toda a Cadeia de Suprimentos”, destaca Eduardo BANZATO.
São os times que promovem “INSIGHTS” e que certamente serão explorados pelos cientistas de dados, iniciando assim projetos que podem ser determinantes para a competitividade na Supply Chain.
02 – Estruturação dos dados: significado e metadados
A partir de inúmeros projetos de implementação de “Data Lake”, observamos que o principal fator relacionado ao sucesso ou fracasso era a concepção incompleta e até ambígua das análises. Embora o conceito “Lago de Dados” na Supply Chain nos permite guardar os dados como eles são/estão, começar projetos sem uma estratégia clara de negócios não é uma boa. E é aqui que os membros sêniores na equipe, que dominam a cadeia de suprimentos, ajudam a mitigar muito esse tipo de risco.
O grande sucesso dos projetos de analytics geralmente está na estratégia do uso dos dados frente às oportunidades de negócio e não necessariamente na tecnologia envolvida. O foco é no “PORQUÊ” e depois no “COMO”.
Além disso, é fundamental o uso sistemático de metadados (informações sobre os dados).
Uma dica importante para quem está começando a organizar a área de Analytics e “Data Lakes” é começar estruturando os dicionários dados.
É fundamental entender a diferença entre a natureza dos dados transacionais e dados analíticos e os seus papéis/expectativas no projeto.
03 – “Stack” tecnológico adequado
Embora a tecnologia seja o segundo passo para a estruturação dos lagos de dados, ela é uma das decisões mais importantes a serem tomadas no projeto. A palavra-chave desse processo é a “Arquitetura de sistemas”.
A escolha do “stack” tecnológico, que representa o conjunto de sistemas necessários para executar um único aplicativo sem outro software adicional é base para a criação do “Data Lake” e deve estar alinhado tanto ao “problema” de Supply Chain (negócio) quanto ao conhecimento técnico do time de operação.
Obviamente, desenhar a arquitetura da(s) solução(ões) demanda profissionais com experiência em engenharia de software, bancos de dados, administração e criação de processos de ETL e escalabilidade de infraestruturas de armazenamento.
04 – Cuidado com superestimativas do volume de dados
Assim como no planejamento e construção de um armazém e/ou centro de distribuição, os projetos de estruturação de “lagos de dados” também necessitam de informações básicas e premissas em uma visão de curto, médio e longo prazo (plano diretor).
Entretanto, muitas vezes, essas informações básicas não ficam claras nem para o time de Supply Chain (negócios) e nem para os arquitetos de sistemas, implicando em sub/super estimativa do volume de dados.
Em relação à superestimativa, já nos deparamos com casos onde que se imaginava um conjunto imenso de dados (muito acima da realidade) para se investigar padrões de comportamentos de uma determinada cadeia de suprimentos (indústria), porém, com o passar do tempo, foi verificado que pequenos ajustes na estratégia de indicadores de desempenho, com o uso de técnicas de amostragem, solucionaram, com inteligência e precisão, mais de 80% dos problemas analíticos.
05 – Cuidado com subestimativas do volume de dados
Claro que, do mesmo modo que é possível superestimar, é também possível subestimar o volume de dados.
Por exemplo, existem inúmeras iniciativas na cadeia de suprimentos vindas de outras áreas, com especial ênfase aos projetos de “IoT” (Internet das Coisas) que, na sua natureza, baseiam-se na obtenção do máximo de dados possíveis provenientes de sensores.
Hoje, muitos profissionais têm dificuldades para identificar esta realidade no curto, no médio e principalmente no longo prazo. E isso implica, de fato, em estratégias de armazenamento, compactação, tipos de análise, segurança e ainda velocidade de transmissão.
Outra forma de subestimação de dados é a exploração combinatória dos registros que, em alguns casos, se tornam computacionalmente inviáveis ao processamento e/ou armazenamento. Assim, são imperativas técnicas apropriadas para cada caso e obviamente, um planejamento bem feito.
06 – Analisar a necessidade do uso de Índices
A criação de índices nos bancos de dados deve estar bem estruturada e não descontrolada. O uso de índices em bancos de dados é uma boa prática que visa aumentar a eficiência de consultas muito frequentes. Isso possibilita ao sistema gerenciador de bancos de dados (SGBD) fazer busca de menor complexidade, evitando as custosas buscas sequenciais.
No entanto, índices ocupam espaço, podendo um índice, muito facilmente, chegar a corresponder a 25% do tamanho de uma tabela.
Em “Data Lakes”, o acesso não é repetitivo, não são necessárias consultas de alto desempenho. Portanto, utilizar índices além de chaves primárias para estabelecer as relações entre entidades pode vir a criar volumes desnecessários para atingir uma eficiência não-desejada.
“Lembre-se que nos livros, os índices são bem menores do que o próprio conteúdo”, destaca Joni Hoppen.
07 – Manter a Segurança
É evidente que onde há informação valiosa há também riscos. A segurança requer um nível de maturidade das estruturas de permissões que, por um lado, permitam acesso rápido e fácil aos analistas e máquinas de analytics, sem comprometer regras de acesso que rompam com o sigilo de determinadas informações.
As soluções mais avançadas de governança de dados que conhecemos usam com maestria a teoria da identidade em seus sistemas, não permitindo assim que haja usuários utilizando acessos de terceiros.
Toda a engenharia de software do projeto deve estar em constante comunicação com os times de Supply (gestão e negócio) para garantir o nível correto de permissão de cada usuário a cada dataset (ou conjuntos de dados) que são o principal insumo dos processos de análise de dados e são representados por dados tabulares, em formato de planilha, onde as linhas são os registros dos acontecimentos e as colunas são suas características.
Atualmente, com a entrada em vigor da Lei Geral de Proteção Dados (LGPD), o fator segurança se torna ainda mais crítico, principalmente nos casos em que os dados armazenados são dados pessoais.
CONCLUSÕES E RECOMENDAÇÕES
As cadeias de suprimentos estão cada vez mais competitivas e, caso sua empresa ainda não percebido, cadeias de suprimentos com mais robustez do ponto de vista de gestão da informação estão se expandindo em um ritmo acelerado (algumas até exponencialmente) e que podem facilmente impactar em absolutamente todos os negócios, inclusive no seu.
Assim, se você e/ou sua empresa já estão conscientes que o poder cada vez mais estará nas mãos daquelas empresas que souberem explorar melhor os dados, considere que:
- o planejamento de curto, médio e longo prazo para a ciência de dados na Supply Chain (Planos Diretores) continua sendo tão importante ou até mais que outros planejamentos corporativos;
- projetos relacionados à estruturação de “data lake”, “big data”, “analytics” geralmente são complexos por natureza e com grandes riscos de se tornarem “pântanos de dados” (“Data Swamps”);
- não existem soluções “mágicas” ou prontas devido ao alto grau de customização dos dados para cada negócio, setor e estratégia empresarial.
Desta forma, desejamos sucesso ao seu “Data Lake”, esperando que sua Cultura de Dados avance cada vez mais em direção à competitividade.
Grato pela atenção e vamos em frente!
Eduardo Banzato e Joni Hoppen
Conteúdos relacionados:
- 6 recomendações de gestão para projetos de Data Lake – Aquarela
- Maturidade de dados: da governança ao data analytics | Aquarela
- DATA SCIENCE & DATA ART – Blog | IMAM
- Transformação Digital na Supply Chain – Blog | IMAM
* Grupo IMAM e Aquarela Advanced Analytics
O Grupo IMAM é uma organização de consultoria e treinamento que há 40 anos se dedica nos temas de Supply Chain e Gestão Competitiva e a Aquarela Analytics é pioneira e atual referência nacional na aplicação de Inteligência Artificial em diferentes segmentos.


